
Коротко: подход Zero Trust — «никогда не доверяй, всегда проверяй» — давно стал базовым для современных инфраструктур. Когда к системам добавляются LLM и автономные AI-агенты с правами доступа к данным и API, старая парадигма периметра перестаёт работать: AI умеет быстро агрегировать, анализировать и действовать на больших объёмах данных, а значит любая уязвимость масштабируется не в десятки записей, а в тысячи или миллионы. Поэтому Zero Trust (ZTA) — основанный на идентичности и минимальных правах — сегодня не просто хорошая идея, а практическая необходимость для безопасного развёртывания AI. (Основа темы — TechRadar).
Главная проблема: ИИ увеличивает количество путей для атак и масштаб ущерба
LLM и автономные агенты по-своему усиливают знакомые риски:
- Масштаб и скорость — агент с доступом к API может выполнить цепочку запросов и за секунды собрать множество конфиденциальных записей. Одна скомпрометированная сессия = огромный объём утечки.
- Сложные цепочки действий — агенты вызывают другие агенты, сервисы и базы данных; отслеживание того, «кто чего попросил», усложняется.
- Новые «не-человеческие» идентичности — сервисные аккаунты, токены, модельные учётки (non-human identities, NHIs) часто имеют постоянные/широкие права и плохо контролируются.
Вывод: традиционные периметры и статические фильтры (фильтрация prompt/output) недостаточны — нужны идентично-ориентированные, контекстно-чувствительные и микроправила, которые налагают ограничения «по действию», «по времени» и «по контексту».
Что такое Zero Trust в контексте ИИ
Классические принципы ZT остаются, но адаптируются под ИИ-контекст:
- Каждое действие требует идентификации и авторизации — не только человек, но и модель/агент/процесс имеет собственную идентичность, роли и права.
- Контекстные, тонкие политики доступа — доступ зависит от фактора: время, роль, локация, метаданные сессии и категория данных.
- Минимальные права + JIT (just-in-time) доступ — выдавать права на действие только тогда, когда это необходимо, и отозвать сразу после.
- Аудит и неизменяемые логи — каждая цепочка вызовов между агентами/моделями/данными должна быть записана и проверяема.
- Контроль цепочек (propagation control) — если агент вызывает другой агент, то система должна проверять полномочия каждого шага и не передавать «статус суперпользователя».
Эти положения логично вытекают из NIST SP 800-207 — базового руководства по Zero Trust. В контексте AI нужно усилить управляющую часть для «non-human identities» и механизмов JIT/PAM.
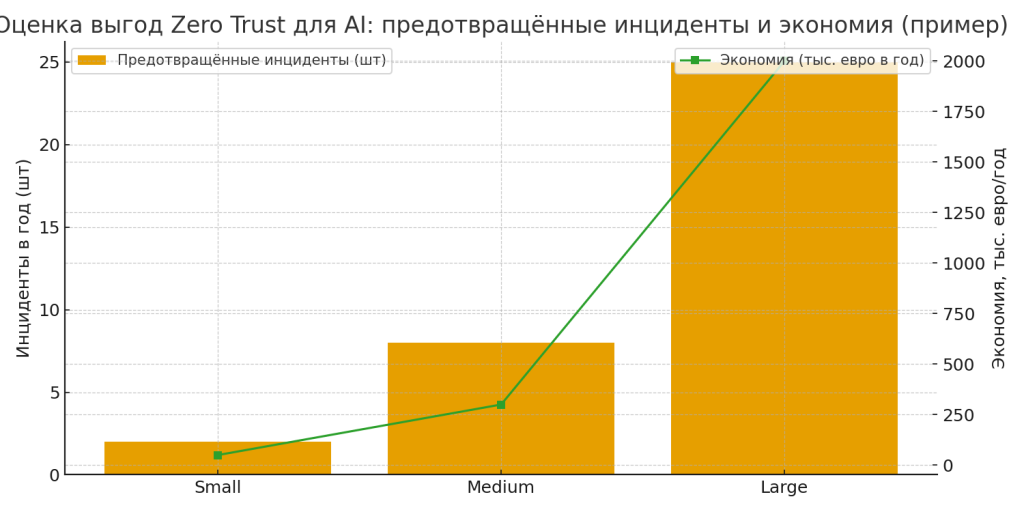
Где Zero Trust даёт самый большой эффект: кейсы и аргументы
a) Предотвращение exfiltration через агента
Если агент по умолчанию не имеет «standing privilege», то промт-инъекция не даёт прав для выгрузки базы — злоумышленник может заставить модель сформировать запрос, но без валидной идентификации на стороне API доступ будет запрещён.
b) Контроль автоматических цепочек действий
Zero Trust позволяет подписывать и прослеживать полномочия вместе с запросом: «агент A может прочитать метаданные, но не экспортировать платежные данные; агент B может создавать тикеты, но только в песочнице».
c) Ограничение вреда при компрометации токенов
JIT-доступ + ревокация и «песочницы» (scoped tokens) уменьшают время жизни украденных токенов и область их действия.
4. Технические элементы внедрения Zero Trust для ИИ (практика)
Ниже — конкретные блоки архитектуры и шаги:
4.1. Идентичность для моделей и агентов (NHIs)
- Каждому агенту / модели — своя identity в IAM: client_id, mTLS-сертификат, short-lived token.
- Принцип: не пользователю = не полномочие — сервисные аккаунты должны иметь минимальный набор прав.
(Примеры и решения в индустрии: Okta и другие IAM встраивают инструменты управления не-человеческими идентичностями и JIT PAM).
4.2. Политики доступа и атрибуция (policy engine)
- Используйте policy engines (OPA, XACML, облачные аналоги) для динамического запрета/разрешения.
- Политики учитывают sensitivity labels (PII/PHI), источник запроса, current session context.
4.3. Just-in-Time (JIT) и least privilege / PAM
- Для критичных операций вызывать approval workflow (human-in-the-loop) или временные права.
- Интеграция с PAM для выдачи привилегий только на короткое время.
4.4. Observability и неизменяемый аудит
- Логируйте цепочки: кто → агент → модель → ресурс, с подписью и таймстампом.
- Используйте WORM-хранилище для логов и SSO-инструменты, чтобы ссылаться на конкретную сессию.
4.5. Контроль содержимого и RAG-изоляция
- Для Retrieval-Augmented Generation (RAG) устанавливайте прослойку: проверяйте, какие документы может подхватить модель и какие фрагменты разрешено возвращать.
- При необходимости используйте «filters + redactors» и динамическое маскирование PII.
Процесс внедрения: roadmap (шаги, приоритеты)
- Discovery & Inventory — найдите все NHIs (сервисные аккаунты, модели, агентов) и точки интеграции AI.
- Классификация данных — какие данные критичны, какие запреты/разрешения нужны.
- Identity baseline — выдайте идентичности в IAM/PKI каждому агенту.
- Пилот с policy engine — настроьте OPA/облачные политики для нескольких рабочих потоков (напр., summary of contracts).
- PAM + JIT — настройте получение прав по заявке и автоматический отзыв.
- Observability & incident playbooks — настройте алерты и runbooks при подозрительных цепочках доступа.
- Развертывание и масштабирование — по вертикалям и по степени риска.
- Audit / continuous improvement — регулярные оценки, red team/blue team и тесты на prompt injection/agent jailbreak.
KPI и метрики успеха (чем измерять)
- TTR (time-to-revoke) — среднее время от обнаружения скомпрометированного токена до его отзыва.
- Снижение зоны экспозиции — доля запросов, которые могли бы получить доступ в legacy но блокируются ZT (процент).
- Количество инцидентов утечки через AI-агентов — абсолютная и относительная динамика.
- Процент транзакций с JIT-авторизацией — практическая мера охвата PAM.
- Время реакции на аномальную цепочку вызовов — SLA SOC / AI security.
Регуляторный ландшафт и требования (как это влияет на Rollout)
Регуляторы (включая требования GDPR и инициативы по AI-гарантиям) уже выдвигают ожидания: организации должны уметь доказать, кто и почему получил доступ к данным, какие меры предприняты для предотвращения неправомерного использования моделей. Zero Trust предоставляет готовую фактуру для auditable controls: identity, scope, logging и minimization — всё это помогает соответствовать требованиям. Внедряя ZT, организации получают не только техническую защиту, но и юридическую доказуемость.
Прогнозы и сценарии (2025–2029) — аналитика и цифры (оценки)
Ниже — набор реалистичных сценариев и связанных прогнозов (иллюстративные оценки, основаны на рыночных публикациях и текущих трендах в IAM/Zero Trust):
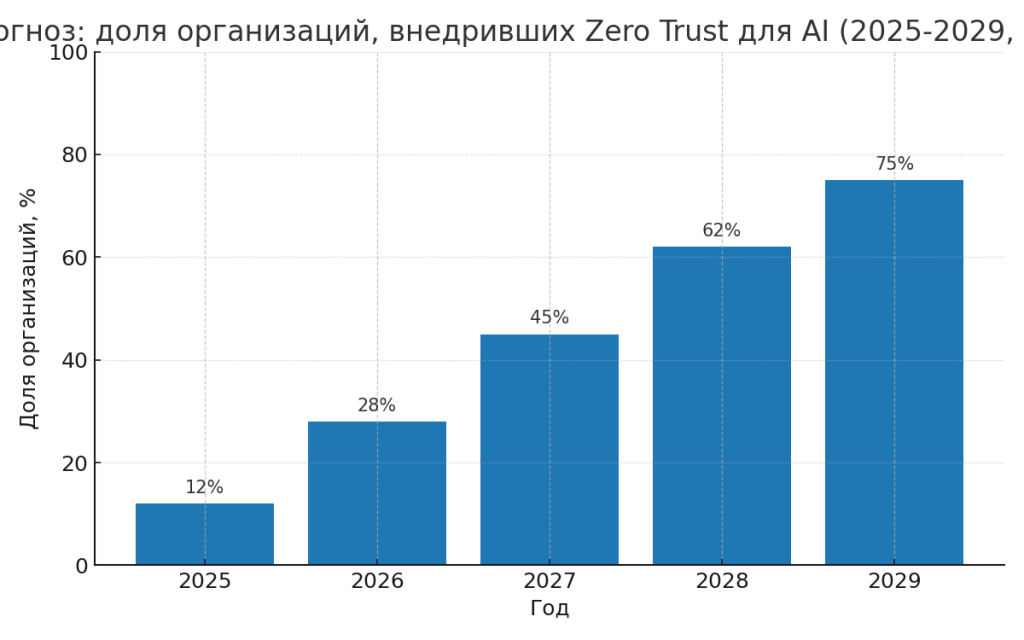
Сценарий 1 — «Ускоренное принятие» (оптимистичный)
- 2025: пилоты и early adopters (12–20% крупных предприятий).
- 2026–2027: быстрый рост — 30–50% организаций в облачной среде внедрят основные ZT-контроли для AI.
- 2028–2029: 60–80% зрелых цифровых организаций будут использовать ZT-паттерны специально для AI-каналов. (график прогноза — в картинках)
Сценарий 2 — «Регулируемая зрелость» (пессимистичный / регулируемый)
- Из-за строгих локальных правил (EU, healthcare) внедрение в этих секторах идёт медленнее — 20–30% к 2027 году.
Влияние на инциденты и экономику (примерные оценки): если организация сократит зону экспозиции AI на 60% благодаря ZT, то потенциальное количество инцидентов, связанных с утечкой через агентов, может упасть в 3–5 раз; прямые экономические потери (штрафы, remediation, репутационный урон) могут сократиться на сопоставимый коэффициент. (См. иллюстративную диаграмму выгод).
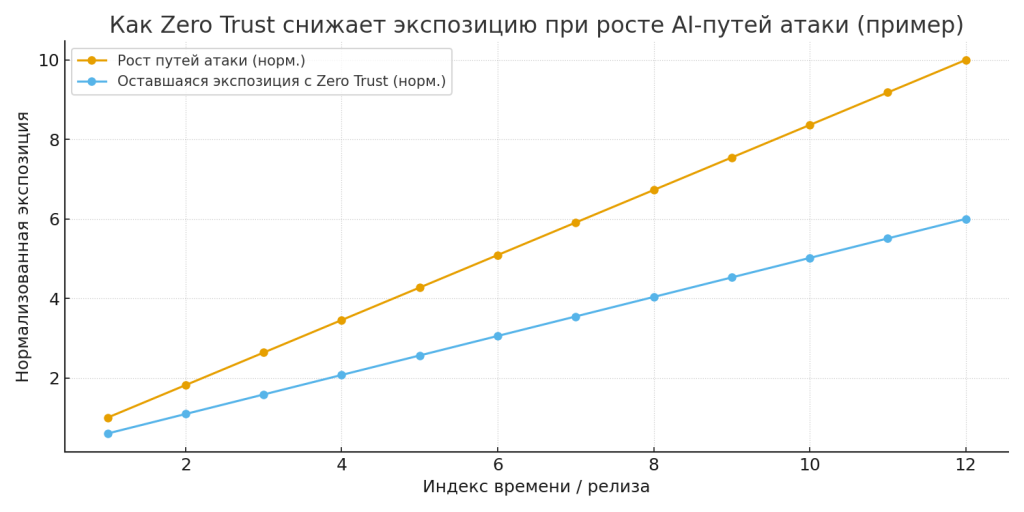
Практические рекомендации (чеклист) — что сделать завтра
- Составьте реестр NHIs — инвентаризация сервисных учёток, моделей, токенов.
- Сегментируйте доступ — операции с PII, платежами и критичными данными — в отдельный сегмент с повышенным контролем.
- Внедрите JIT-доступ для операций с высокими рисками.
- Подключите policy engine (OPA или облачный эквивалент) — управляйте в одном месте.
- Настройте неизменяемую трассировку цепочек вызовов — запись «agent A запросил X; agent B выполнил Y».
- Репериодически тестируйте prompt injection / agent jailbreak с red-team.
- Установите бизнес-метрики и SLA: TTR, % автодоступов, число инцидентов.
Ограничения и риск «переусложнения»
Zero Trust — это не магическая кнопка. Его внедрение требует усилий: согласование политик, переработка сервисной архитектуры, обучение команд. Неправильная настройка может приводить к отказу сервисов и к увеличению операционной нагрузки. Поэтому подход «пилот → автоматизация → расширение» оптимален: начать с пары критичных рабочих потоков и постепенно масштабировать.
Заключение — почему стоит начать сейчас
AI даёт огромные выгоды, но одновременно увеличивает масштаб ущерба от ошибок и злоупотреблений. Zero Trust — проверенная архитектурная парадигма — естественным образом переводит безопасность в модель, пригодную для машинной скорости решения: выдача прав по требованию, динамическая авторизация, слежение и ретроспективная проверка. Организации, которые заранее выстроят идентичностно-ориентированную защиту и JIT-контроль для AI, получат конкурентное преимущество: быстрее масштабировать AI-инициативы, одновременно снижая риск утечек и регуляторных штрафов.